AI / Document Processing
AI Document Intelligence Platform
How two engineers built an LLM-powered document processing platform - from hardcoded extraction to dynamic schema generation - for a seed-stage startup.
Overview
A seed-stage startup came to us with a clear thesis: paper-heavy operational businesses - manufacturing, logistics, field services - are sitting on mountains of unstructured documents that lock up critical data. Purchase orders, invoices, inspection reports, compliance certificates - all trapped in PDFs and scanned images, manually re-keyed into spreadsheets and ERPs.
They needed engineers who could own the entire technical build. A small team, shipping fast, making architectural decisions independently. We started on the MVP. Six weeks later, we’d shipped well beyond the original scope - a full document intelligence platform with an AI chatbot, a dashboard builder, and infrastructure that deploys on every merge to main.
The Challenge
Operational businesses generate enormous volumes of documents. A single manufacturing plant might process hundreds of purchase orders, delivery receipts, and quality certificates per week. The data in those documents is valuable - it feeds procurement decisions, compliance tracking, inventory management - but extracting it is manual, slow, and error-prone.
The startup’s bet was that LLMs had made document understanding good enough to automate this at scale. But “good enough” in a demo is different from “good enough” in production. The platform needed to handle arbitrary document types, adapt to each customer’s unique schemas, and deliver structured data reliably enough to replace manual workflows.
The technical challenge wasn’t just calling an LLM API. It was building the architecture around it - schema management, caching, error handling, multi-tenant isolation - that turns an AI capability into a product.
What We Built
Dynamic Document Schema Engine
This is the core of the platform, and its evolution tells the story of the entire build.
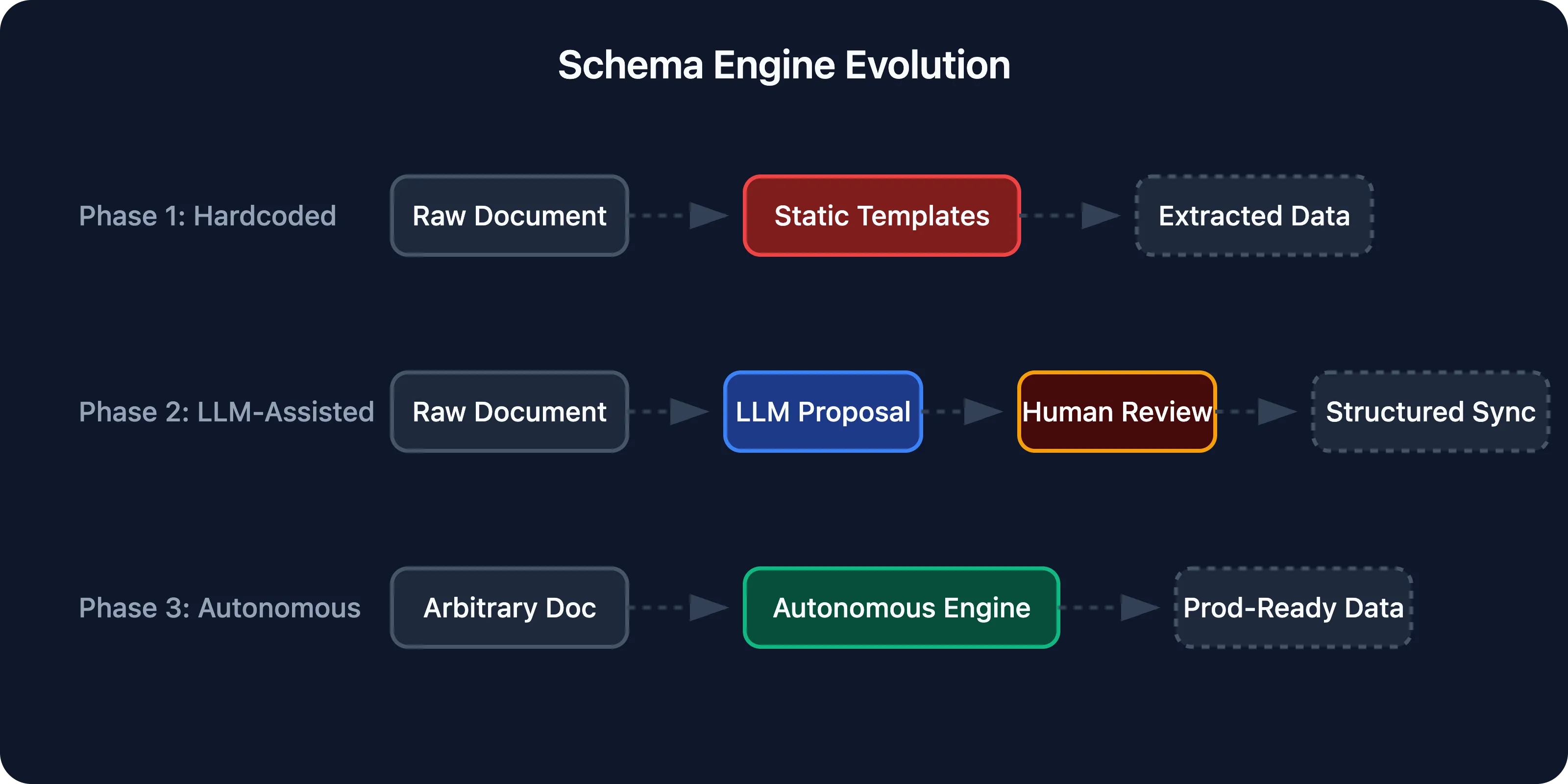
Phase 1: Hardcoded extraction. We started with a fixed set of document types - purchase orders, invoices - with predefined schemas. The LLM extracted fields according to a rigid template. It worked, but every new document type required engineering time to define the schema.
Phase 2: LLM-assisted schema creation. We moved to a system where users could describe a document type in natural language, and the LLM would propose a structured schema - field names, types, validation rules. A human would review and adjust. New document types went from days of engineering to minutes of configuration.
Phase 3: Fully autonomous schema generation. The final architecture removes the human from schema creation entirely. Upload a sample document, and the system analyzes it, generates an appropriate extraction schema, and begins processing. The schema engine handles nested structures, repeating groups (like line items on a PO), cross-field validation, and format normalization. Users can still fine-tune, but the default output is production-ready.
This progression - hardcoded → LLM-assisted → fully autonomous - happened within the six-week build. Each phase shipped to the pilot customer and informed the next.
AI-Powered Chatbot with MCP Connectors
We built a conversational interface that lets users query their document data naturally. Instead of writing database queries or navigating dashboard filters, users ask questions: “What were our top suppliers by volume last quarter?” or “Show me all inspection failures from Building C.”
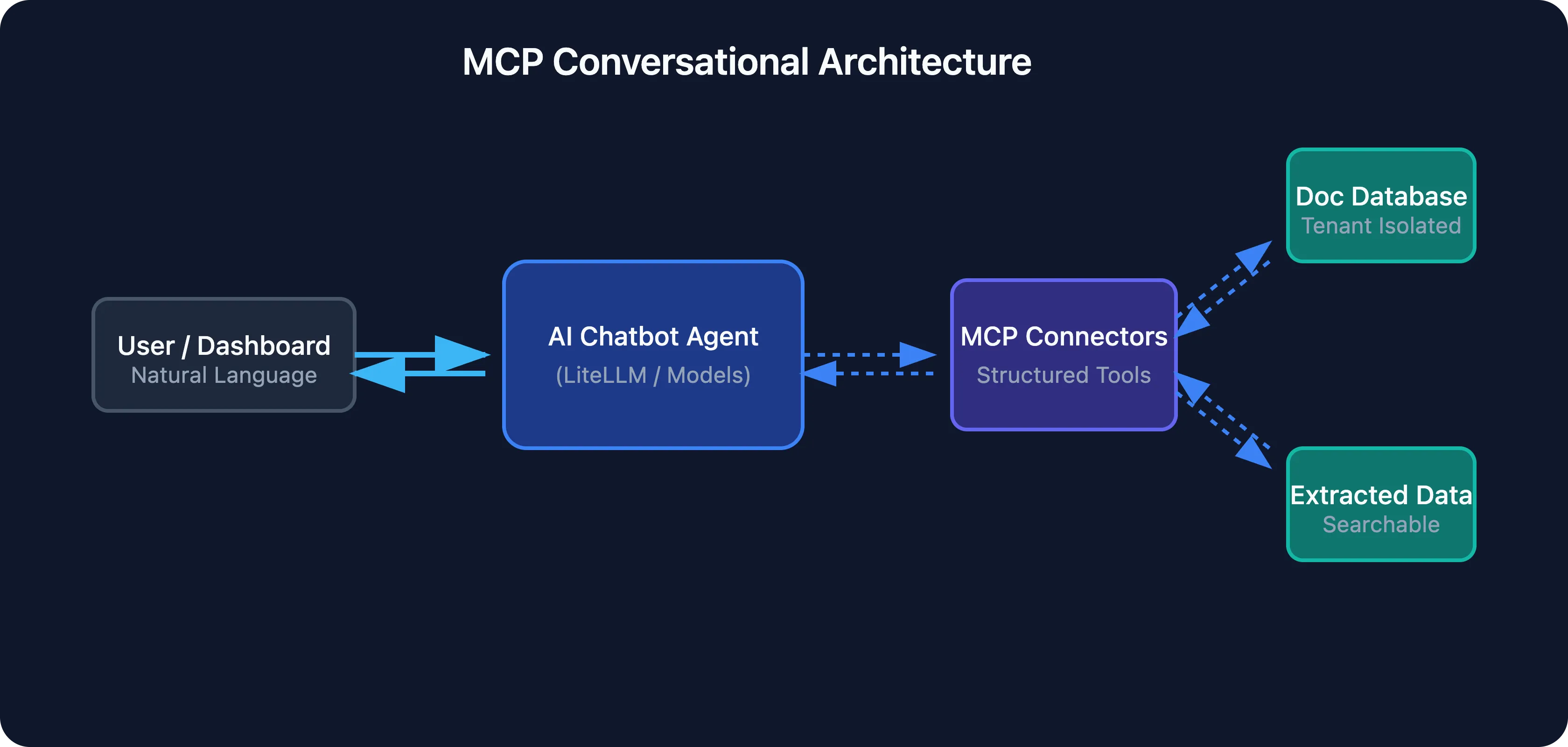
The chatbot is backed by MCP (Model Context Protocol) connectors that give the LLM structured access to the platform’s database. The connectors expose queryable data sources - extracted document fields, processing metadata, user-defined tags - through a consistent interface. The LLM translates natural language into precise data queries, executes them through the connectors, and presents results in context.
This architecture means the chatbot’s capabilities grow automatically as new document types and data sources are added. No retraining, no prompt engineering per feature - the MCP layer handles the abstraction.
We even connected the chatbot to legacy systems. The pilot customer ran QuickBooks Desktop - no cloud API, no REST endpoints, just a Win32 application sitting on a local server. We built a lightweight Windows wrapper application that launches on the client’s machine, establishes a persistent WebSocket connection back to our platform, and bridges bidirectional data flow between QuickBooks Desktop and the chatbot. Users can query their accounting data and push extracted document records into QuickBooks through natural conversation, without ever opening the desktop app.
Dashboard Builder
Users needed to visualize trends and patterns across their processed documents. Rather than building a fixed set of reports, we built a dashboard creation system.
Users describe what they want to see - “a breakdown of purchase order values by supplier over the last 6 months” - and the AI generates a single-page dashboard with appropriate chart types, filters, and data bindings. Dashboards support drag-and-drop layout customization after generation. Users can adjust, rearrange, and add components without touching the AI again.
Dashboards can be password-protected and shared via URL. When a viewer hits a protected dashboard, the server validates credentials before serving any data - no client-side overlay that someone could bypass with inspect element. The dashboard content simply doesn’t reach the browser until authentication passes.
The dashboard builder sits on top of the same data layer the chatbot uses, so any data accessible via conversation is also available for visualization.
Smart Caching Architecture
LLM calls are slow and expensive. For a document processing platform handling hundreds of documents per day, naive LLM usage would be both cost-prohibitive and unacceptably slow.
We implemented a two-layer caching strategy:
Query cache. When the chatbot or dashboard builder generates a data query, the result is cached with a content-addressable key derived from the query parameters and the underlying data version. Identical questions hit cache instead of re-querying. The cache invalidates automatically when new documents are processed or existing data is updated.
Presentation cache. LLM-generated responses - formatted answers, chart configurations, schema suggestions - are cached at the presentation layer. If the underlying data hasn’t changed and the question is semantically equivalent, the cached presentation is served directly, bypassing the LLM entirely.
Together, these layers reduced LLM costs significantly and brought response times for repeated queries from seconds to milliseconds.
Infrastructure
The platform runs on AWS with infrastructure defined as code. The deployment pipeline is deliberately simple: merge to main, and it deploys. No staging environment gymnastics, no manual approval gates. Automated tests and type checking run in CI; if they pass, the code ships.
This wasn’t just a DevOps convenience - it was a product decision. Shipping every few days meant the pilot customer saw continuous improvement. Feedback loops stayed tight. Features that didn’t land right got iterated on within days, not sprints.
Technical Architecture
The stack reflects the priorities of a seed-stage AI product: move fast, keep the AI layer flexible, and don’t over-engineer the infrastructure.
- Backend: Python / FastAPI - chosen for the AI/ML ecosystem. LLM orchestration, document processing pipelines, and API layer all in Python
- LLM orchestration: LiteLLM for model abstraction (swap providers without code changes), Google ADK for agent workflows
- Frontend: React / TypeScript - dashboard UI, document viewer, schema editor, chat interface
- AI connectors: MCP protocol for structured LLM-to-database communication
- Infrastructure: AWS, infrastructure as code, single-merge-to-main deploys
- Data: Multi-tenant isolation, per-customer schema storage, versioned extraction results
Key architectural decisions:
- LiteLLM as the model layer - the startup needed to evaluate multiple LLM providers without rewriting integration code. LiteLLM’s unified interface made provider switches a configuration change
- MCP for data access - rather than baking database queries into prompts, MCP connectors give the LLM a structured, auditable interface to the data layer. This made the chatbot’s data access both more reliable and more extensible
- Schema versioning - as the schema engine evolved, extraction results needed to be tied to the schema version that produced them. This prevents silent data inconsistencies when schemas are updated
- Tenant isolation everywhere - operational businesses handling POs and compliance docs need strict data boundaries. Every layer enforces tenant isolation: database queries, LLM tool calls, query and presentation caches, MCP connectors. No tenant can see or influence another tenant’s data, even through the AI layer
Results
The platform launched into production with a pilot customer within the six-week build window. Early results from the pilot:
- ~500 documents processed per week - purchase orders, invoices, inspection reports, and compliance certificates flowing through the extraction pipeline
- ~90% extraction accuracy out of the box on new document types, with zero manual schema configuration - the autonomous schema engine handles it
- Manual data entry reduced by roughly 80% - what used to take a back-office team hours per day now happens automatically on upload
- Chatbot query response under 200ms on cached queries, under 3 seconds for novel questions hitting the LLM
- 5+ customers in the active sales pipeline, onboarding against the shipped platform
- Exceeded MVP scope - the original brief was document extraction. We shipped extraction, a chatbot, a dashboard builder, and production infrastructure
- Schema engine evolution - three architectural generations in six weeks, each driven by real usage feedback
How We Work
This project was two engineers and Claude Code for six weeks. No project manager, no sprint ceremonies, no handoff documents. Direct communication with the founder, shipping working software every few days.
Most of the code was written by Claude Code, with both engineers pair-programming alongside it - reviewing every line, every reasoning step, keeping the architecture aligned. This isn’t “vibe coding” where you accept whatever the AI generates. It’s a senior engineer watching over the AI’s shoulder, steering decisions, catching the subtle mistakes that compound into architectural debt. The AI writes fast; the human ensures it writes right.
The speed came from this combination. When your team is making the architectural decisions and pair-programming with AI and deploying to production, there’s no translation loss. A conversation about “could the schema engine generate schemas automatically?” turns into a shipped feature by end of week - because the people hearing the idea are the people building it.
This is the model we believe in: senior engineers who own outcomes, not tickets - amplified by AI tooling that lets a two-person team ship what used to require ten. The startup got a production AI platform in the time it would take most teams to finish discovery.
Building an AI-powered product and want to know if your architecture will hold? Get an audit. Ready to ship? Let’s talk.
Related services
Related industries
Have a similar project?
Tell us about what you're building and we'll figure out how we can help.
Get in touch